Demonstrating Success in Cloud and Edge Applications
Edge Implementation
Our edge demo executes the Meta Llama 2, 3.0, 3.1 and Llama 3.2 models, as well as Microsoft Phi-2 LLM 2.7B model on cost-effective AMD Versal FPGA devices, achieving interactive speeds on the vanilla LLM even without quantization, this allows extracting the highest precision: achieving the maximum intelligence of the AI model or, optionally, using Quantization to obtain the maximum speed.
This demo does not need external CPUs, being perfectly suited for stand-alone, low-cost products.

Cloud Implementation
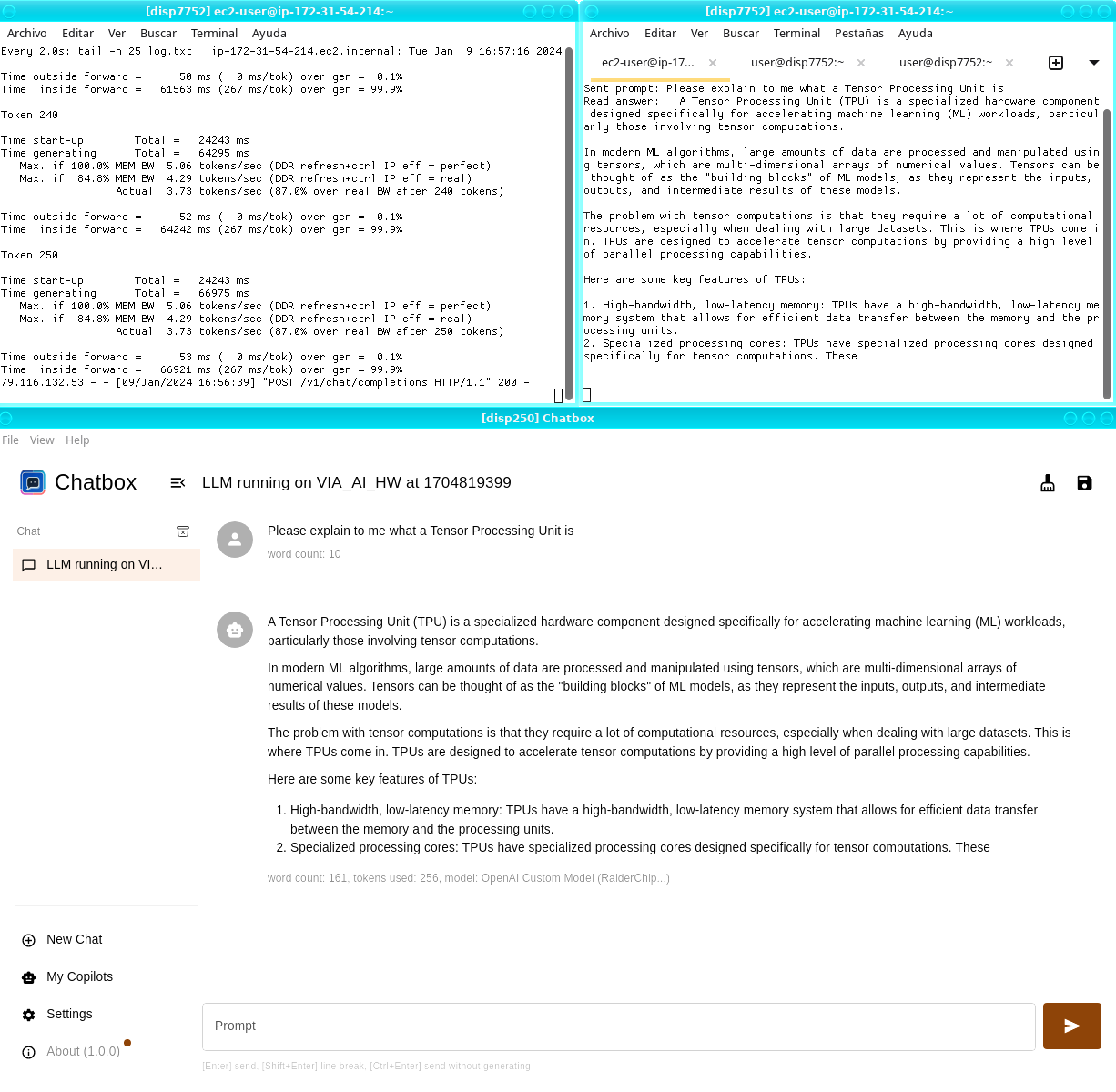
Integrated with AMD FPGAs in the AWS cloud, our cloud demonstrator leverages AWS F1 instances carrying AMD Virtex UltraScale+ FPGAs. This setup has enabled us to showcase a compelling and engaging AI chat model (Llama 2-7B), accessible via a web server for remote interactions, mirroring ChatGPT-style applications.