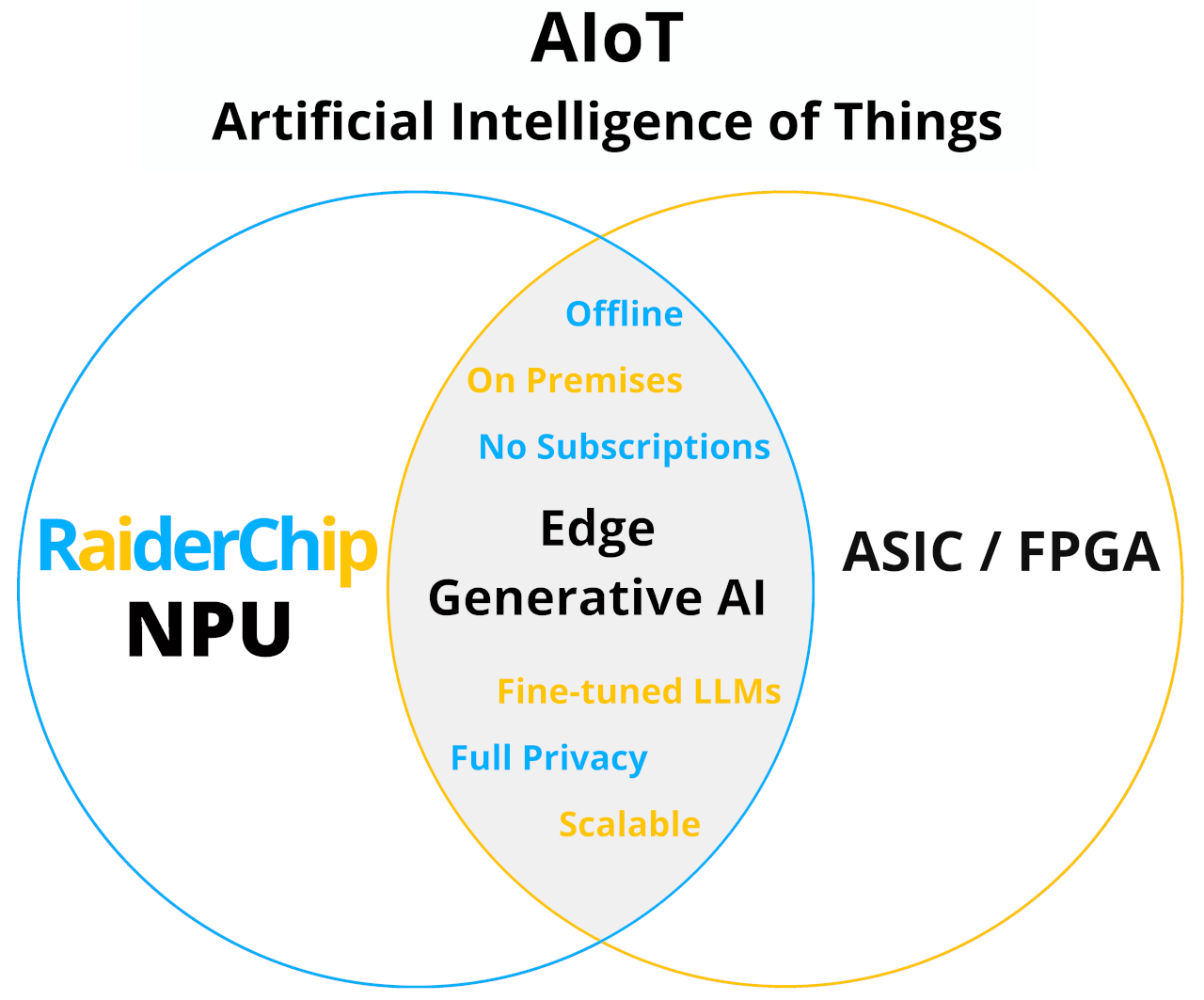
— Our IP —
The GenAI IP is the smallest version of our NPU, tailored to small devices such as FPGAs and Adaptive SoCs, where the maximum Frequency is limited (<=250 MHz) and Memory Bandwidth is lower (<=100 GB/s).
For the highest throughput versions of RaiderChip NPU, please see Kairós Edge AI and Aión Cloud AI ASIC devices. You can also draft your own AI accelerator in a few steps with a Custom NPU